
Improved Semi-supervised Clustering Algorithm Based on Affinity Propagation
2015-01-12 08:32:25JINRanLIURuijuan劉瑞娟LIYefeng李曄鋒KOUChunhai寇春海
JIN Ran (金 冉), LIU Rui-juan(劉瑞娟), LI Ye-feng(李曄鋒), KOU Chun-hai (寇春海), 3
1 College of Information Science and Technology, Donghua University, Shanghai 201620, China2 College of Computer Science and Technology, Zhejiang Wanli University, Ningbo 315100, China3 College of Science, Donghua University, Shanghai 201620, China
Improved Semi-supervised Clustering Algorithm Based on Affinity Propagation
JIN Ran (金 冉)1, 2, LIU Rui-juan(劉瑞娟)1, LI Ye-feng(李曄鋒)1, KOU Chun-hai (寇春海)1, 3
1CollegeofInformationScienceandTechnology,DonghuaUniversity,Shanghai201620,China2CollegeofComputerScienceandTechnology,ZhejiangWanliUniversity,Ningbo315100,China3CollegeofScience,DonghuaUniversity,Shanghai201620,China
A clustering algorithm for semi-supervised affinity propagation based on layered combination is proposed in this paper in light of existing flaws. To improve accuracy of the algorithm, it introduces the idea of layered combination, divides an affinity propagation clustering (APC) process into several hierarchies evenly, draws samples from data of each hierarchy according to weight, and executes semi-supervised learning through construction of pairwise constraints and use of submanifold label mapping, weighting and combining clustering results of all hierarchies by combined promotion. It is shown by theoretical analysis and experimental result that clustering accuracy and computation complexity of the semi-supervised affinity propagation clustering algorithm based on layered combination (SAP-LC algorithm) have been greatly improved.
semi-supervisedclustering;affinitypropagation(AP);layeredcombination;computationcomplexity;combinedpromotion
Introduction
Clustering algorithm, an efficient data analysis method, conducts clustering analysis to data without prior information, which is also called unsupervised learning method. Such a traditional clustering algorithm cannot generate effective results because data are not provided with prior analysis in practical issues; but we gain prior knowledge of a few data sometimes, including constraints for dividing class labels and data points (such as pairwise constraints). It is of vital importance about how to make use of a little prior knowledge to conduct clustering analysis of lots of data without prior knowledge, and semi-supervised clustering is proposed to assist in unsupervised clustering by a few data provided with prior knowledge. Therefore, semi-supervised clustering has gradually become a focal spot in the study of clustering analysis[1-19].
Existing semi-supervised clustering algorithm can be divided into three classes. The first is constraint-based semi-supervised clustering method (CBSSC)[10-11, 20-21]which usually guides clustering processes by pairwise constraints of must-link and cannot-link. Must-link constraint stipulates: if two samples belong to must-link constraint, they must be assigned to a clustering; but cannot-link constraint correspondingly stipulates: if two samples belong to cannot-link constraint, they cannot be assigned to a clustering. The second is distance-based semi-supervised clustering (DBSSC) method[16, 18, 22]which learns the distance measure by pairwise constraint so as to change the distance between samples and make for clustering. The last is constraint and distance based semi-supervised clustering method (CDBSSC)[7-8]which is the combination of the above-mentioned two methods actually. Although three methods instruct clustering by pairwise constraints, pairwise constraints are often violated in solving processes, resulting in unsatisfactory clustering results. For example, DBSSC learns a distance function by must-link and cannot-link to change the distance between samples and raise performance of clustering. But it cannot guarantee that must-link dot pairs can be always divided into a clustering group after the distance between samples is changed; while a part of cannot-link dot pairs are assigned into a clustering so that constraints are violated. CBSSC is an infringement trying to solve pairwise constraints through adding penalty terms in the objective function ofk-means. However, it is a difficulty to choose a proper penalty factor. Thereby, it still cannot settle constraint violation because it carries on disadvantages of the former methods and fails to figure out an effective solution. Moreover, three methods mentioned above are only suitable for lower-dimension sample data but disabled to higher-dimension data, because the distance between sample dot pairs of different data distributions and different distance functions in high-dimension data space is almost identical.
Affinity propagation clustering (APC) can process large-scale data faster with better clustering result compared with previous clustering methods. It is also applied to facial image clustering, identification of genetic expression data, hand-printed character recognition and optimal aerial route in references. It is shown in the experimental result that APC can generate the clustering results in a short time for whichk-Medoids needs to spend a long time. Another advantage of APC is that it does not require the symmetry of similar data-established matrixes, enlarging its applied range. Nevertheless, the affinity propagation (AP) algorithm is a centre-based clustering method with good performance of compact peroblate-distributed dataset and is unsuitable for clustering issues of complex shape. Furthermore, clustering performance needs further improvement. It costs a lot of time to construct similarity matrixes with the rapid growth of the samples, so the computation complexity should be reduced. Inmar and Brendan[23]investigated semi-supervised clustering for AP (SSAP) where pairwise constraints (both cannot-link and must-link) guided the clustering algorithm. However, this algorithm lacks flexibility because the constraints have to be satisfied in every step. Its computation is cumbersome. Xiao and Yu[24]put forward a semi-supervised clustering method based on affinity propagation algorithm (semi-supervised clustering based on affinity propagation algorithm, SAP) which adjusted similarity matrix by pairwise constrains of data points, and clustering performance of AP algorithm was improved. However, it is extremely limited to win user’s prior information. Besides, clustering processes may be misled when prior information contains noise. Dongetal.[25]designed an APC based on variable similarity measure (AP-VSM) which improved the similarity matrix and the clustering accuracy through shortening the distance between data at a manifold and enlarging that in indifferent manifold areas. But the similarity measure between any two data points should be calculated to raise the computation complexity.
To improve the accuracy of clustering and reduce the complexity, a semi-supervised AP clustering algorithm based on layered combination (SAP-LC) is proposed in the paper. Different from SAP and AP-VSM, SAP-LC has the characteristics of guiding clustering by semi-supervised mechanism, reducing computation complexity by layered clustering, and boosting clustering accuracy by Adaboost combined promotion[13].
The rest of this paper is organized as follows. Section 1 states related works. Section 2 demonstrates clustering idea of layered combination. Section 3 states SAP-LC. Section 4 demonstrates the experimental results. Conclusions are drawn in section 5.
1 Analysis of APC
Suppose that the datasetXis {x1,x2, …,xN} and some compact clustering in the characteristic space of dataC={c1,c2, …,cK} exists. Each data point only corresponds a clustering. Supposing thatxc(i)presents the clustering representative point of any pointxi, which includes natural number. Then, the error function of clustering is defined as

(1)
AP algorithm aims to seek the set of optimal representative points so as to figure out the minimum error function, namely
C*=argmin[J(C)].
(2)
In the formula,Nsample points of the dataset are regarded asNcandidate clustering centres first, and then information of attraction degree is conducted between each sample point and others, namely similarity between sample pointsxiandxjwhich can be established according to the research problem and doesn’t need to not to meet constraints of Euclidean space in practical use. Moreover, similarity is often established as a negative number of the square of two Euclidean distances in traditional clustering problems.
s(i, j)=-d2(xi, xj)=-‖xi-xj‖2, i≠j.
(3)
In this formula,s(i,j) is stored in the similarity matrixSN×N, indicating the degree when the data point is suitable for the class representative point ofxj.xiattracts near points more. Ifxiis at the centre, the sum of attraction to other data points is larger and the more probable it becomes the clustering centre. Ifxiis at the edge, the sum of attraction is small and the probability is less to become the clustering centre.
AP algorithm introduces two important parameters of information content, which arer(i,j)(responsibility) anda(i,j) (availability). Their alternating updating is the iterative process of AP algorithm and they represent different competition purposes. As Fig.1 showsr(i,j) represents accumulated evidences ofxj, and it points fromxitoxj. It is used to show the degree thatxjis suitable for the class representative point ofxi.a(i,j) represents accumulated evidences ofxi, and it points fromxjtoxi. It is used to show the degree thatxiis suitable for the class representative point ofxj. The core step of AP algorithm lies in the alternating updating process of two information contents; the update formula takes on as follows:

(4)

(5)

Fig.1 The amount of information transmission
AP algorithm introduces another important parameterλinto information updating, called damping factor.r(i,j) anda(i,j) are updated through weighting the updating value of current iterative process and the previous iteration in each loop iteration for avoidance of numerical oscillation. The weighting updating formula takes on as follows:

(6)
(7)
In the formula,λ∈[0, 1) is a damping factor to inprove convergence, and the default value is 0.5. When the class number generated by AP algorithm in the iterative process vibrates unceasingly and cannot be converged, increasingλcan eliminate the vibrations.
It can be seen from the executing process of AP algorithm that every data point is regarded as a class representative point. Thus, the clustering is not restrained by the initial class representative point, and large-scale multiclass data is disposed fast. However, AP algorithm is a centre-based clustering algorithm, it has good clustering performance in compact peroblate-distributed dataset and is unsuitable for multi-scale clustering problems with any space and shape.
2 Clustering Idea of Layered Combination
2.1 Semi-supervised Layered clustering
SAP-LC algorithm applies layered clustering method and divides an APC ofNdata points intoN/Msemi-supervised APC equally, andMsamples are sampled from each clustering according to the weight of each data point. However, the semi-supervised idea is shown in constructing pairwise constraints and mapping class labels by virtue of a few known data points.


Fig.2 The diagram of layered sampling treatment
Thismethodisprovidedwiththefollowingadvantages.Itconductslayeredsamplingandclusteringforlarge-scaledatasets,easyoperationandrealization.Datapointstreatedoneachlayeraredifficultclusteringdatawithgoodrepresentativeness.Clusteringisexecutedoneachlayerwhereweightedarrayvotingisconductedsoastodeterminethesubmanifoldtowhicheachdatapointbelongsandimprovetheclusteringaccuracy.



③ delivery of must-link constraint:

④ delivery of cannot-link constraint:

Adjust the similarity matrixSM×MofMsamples sampled from each layer based on the above principles, and iteratively renew information contents by AP algorithm. It can make the similar data points be classified as the same class because of the maximization of attractive force. The different data points are seperated forcefully because of minimization of attractive force, so as to improve performances of clustering algorithm.
(3) Submanifold label mapping. Submanifold label mapping determines the class according to the clustering label of data points by two following steps.
Step 1 Initialize the class label ofXu

Step 2 Determine the mapping function of submanifold label
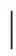

(8)
It can be seen from Formula (8) that the label mapping function of submanifold is

(9)
2.2 Combined promotion method
Adaboost algorithm aims to promote the accuracy of given sorting algorithms in machine learning based on the idea that: the weight of self-adaption iteratively-trained sample enables the base sorter to be focused on “difficult” data samples. Combine and overlay by base sorter with ordinary sorting capacity and certain method. Generate a strong sorter. It is proved by theories that as long as every base sorter has better sorting capacity than random guess, the error rate of the stronger sorter is approximate to 0 when there are boundless base sorters[26].
Inspired by Adaboost sorting algorithm, SAP-LC promotes the accuracy of the clustering result through weighted array of the clustering result on each layer based on semi-supervised layered clustering. It can be seen in Fig.3 that SAP-LC algorithm contains three steps: layered sampling of data, semi-supervised AP clustering ofT=「N/M? subsets, and confirm clustering label of data points by combined voting.

Fig.3 The logical flow figure of SAP-LC algorithm
3 SAP-LC
3.1 Detailed process
The main ideal of SAP-LC algorithm consists of the following parts. Firstly, conduct initialized label to unknown label sets by 1NN method. Secondly, divide an AP clustering ofNdata points intoN/Msemi-supervised AP clustering equally based on the idea of dividing and ruling. Thirdly, construct pairwise point constraints to improve the similarity matrix in the layered semi-supervised AP clustering and conducting label mapping to submanifold. Finally, elevate the accuracy of clustering by combined promotion based on Adaboost.
The description of SAP-LC algorithm is shown as follows.

Use a few labelled datasetsXlto conduct initialized label toXuby 1NN.
Do fort=1, 2, …,T


(c)AdjustSM×Mby pairwise point constraints of labeled data points.
(d) Cluster by AP algorithm according to Formulas (6) and (7) and figure outm′ submanifold.
(e) Conduct label mapping to submanifold according to formula (9) and confirm the class labellt(xi) of each sampled point.

resetwi=1/N(i=1, 2, …,N) and return step (a).
end if

end for

3.2 Analysis of algorithm accuracy

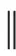
If there is a guess variablehand ?ht The higher the clustering accuracy of each layer than the random guess is, the faster the clustering error reduces. The clustering error is in exponential decrease by degrees to increase of iterative steps, and the algorithm convergence is faster. 3.3 Analysis of computation complexity It can be seen from learning process of AP clustering that the computation complexity of AP clustering is mainly used for construction of the similarity matrix and iteration of information content. The former isO(N2), and the time that iteration of information content costs is determined by iterations. So the time complexity of the whole algorithm is not higher than the time that AP clustering costs in the most iterations, but the least is not less thanO(N2). Generally speaking, the algorithm will not reach the most iterations unless it is not converged. Thus, we may as well suppose the computation complexity isO(ηN2), thereinto, 1<η?N. In the paper, 16 datasets are chosen for clustering comparison of AP, SAP, AP-VSM and SAP-LC[27]. 4.1 Experimental data 4.2 Algorithm effectiveness index Three indexes are used to evaluate the clustering result in the experiment: normalized mutual information (NMI), overall accuracy rate and computation time. Definition 1 Normalized mutual information (NMI) IfCis the class label of sample after clustering andYis the original label, NMI is expressed as (11) Thereinto,I(C;Y)=H(Y)-H(Y|C) is the mutual information betweenCandY,H(Y) is the Shannon entropy ofY, andH(Y|C) is the conditional entropy ofYunder given conditions ofC. The value of NMI is between 0 and 1. The large the value is, the better the performance of clustering is. Definition 2 Overall accuracy rate (12) Definition 3 Computation complexity As for a dataset, computation complexity is the execution time of clustering algorithm. 4.3 Experimental results and analysis (1) Comparison of NMI As for UCI datasets, AP, SAP, AP-VSM and SAP-LC are used for clustering respectively. Table 1 shows NMI values of the four algorithms executed on the 16 datasets. Table 1 Comparison of NMI value DatasetInstanceAPSAPAP-VSMSAP-LCIonosphere3510.51660.57520.72500.6984Iris1500.75620.83740.90540.9141Letter200000.26500.50120.56320.6107Soybean470.60870.76890.86470.9202Vehicle8460.37650.47120.50590.6754Pendigits109920.37350.54100.62430.7061Optdigits56200.48120.51710.63070.7821Sick37720.54730.81100.63980.8028Car3920.50810.56190.71200.7817Anneal7980.40240.56150.53010.7214Dermatology3660.51860.60120.76120.8210Different3000.42130.48470.56710.5987Same2950.28300.45170.50910.5655Similar2880.35330.54310.70350.7233YaleB1100.57660.71280.81210.8898ORL1000.55890.62450.78900.8568 It can be seen from Table 1 that SAP-LC’s NMI value acquires absolute advantages, and the second is AP-VSM. AP-VSM’s NMI value has good effect in ionosphere dataset. SAP is in the ascendant in sick dataset. SAP-LC’s NMI value is also obviously higher than that of other three algorithms as for Different, Same, Similar, YaleB and ORL high-dimension dataset. (2) Comparison of overall accuracy rate The overall accuracy rate is calculated according to Definition 2. The overall accuracy rate of the four algorithms is compared in Table 2, and both SAP and SAP-LC use 10% of label rate. Meanwhile, 20 experimental simulations are conducted in light of each dataset and algorithm, and corresponding average value and variance are calculated. SAP-LC’s accuracy rate is improved more than AP’s, which is obviously higher than SAP and AP-VSM. In particular, the accuracy rates of Pendigits, Optdigits, Sick, YaleB and ORL datasets have been improved obviously. Clustering performances have been improved to some extent since AP’s similarity matrix has been boosted by SAP and AP-VSM. SAP-LC uses combined promotion to reduce the clustering error exponentially, resulting in the best clustering result. Table 2 Comparison of overall accuracy rate of algorithm/% DatasetInstanceAP/%SAP/%AP-VSM/%SAP-LC/%Letter2000056.25±1.8972.15±1.3776.80±3.5983.20±0.71Pendigits1099276.41±1.5987.28±1.5391.79±1.3098.83±0.15Optdigits562070.46±2.2578.37±3.6889.16±0.6894.35±0.60Sick377292.12±1.0996.31±0.6595.95±0.2297.37±1.61Ionosphere35166.02±0.3071.02±1.2688.41±3.5085.05±3.59Iris15044.77±0.5258.29±0.1966.34±3.6867.09±4.41Soybean4748.79±0.9061.68±2.9576.48±1.9982.39±2.40Vehicle84651.66±3.9458.21±2.5560.85±2.1072.26±1.52Car39263.37±0.7767.70±1.8872.10±0.8982.41±3.90Anneal79871.68±0.0973.88±0.1974.87±1.5982.79±2.11Dermatology36652.67±1.3953.11±0.6075.13±2.2377.10±0.26Different30058.14±1.4361.81±2.2072.11±1.7283.03±3.28Same29553.49±0.8559.02±1.3977.41±2.0181.55±1.19Similar28850.73±2.0669.25±1.8680.27±3.1386.21±2.29YaleB11077.42±1.3182.71±2.2789.03±1.0296.50±0.27ORL10076.16±1.7984.20±2.1591.41±0.7297.04±0.15 As for four datasets: anneal, car, soybean and letter, change rules of the overall accuracy rate to the labeling rate is simulated in Figs.4-7. We can see that the overall accuracy rates of unsupervised AP and AP-VSM vibrate slightly to the labeling rate but do not increase obviously, while those of semi-supervised SAP and SAP-LC change greatly because both guide clustering by a few labeled data. The more data points are labeled, the closer to life the clustering learning is. Fig.4 Accuracy rate of anneal dataset Fig.5 Accuracy rate of car dataset Fig.6 Accuracy rate of soybean dataset Fig.7 Accuracy rate of letter dataset (3) Comparison of computation complexity The computation time is compared in Fig.8 in light of four datasets with larger data size (Letter, Pendigits, Optdigits, Sick). This experiment is conducted on an Intel Core i5 2.4 GHz processor with 4 G memory and 320 G hard disk. Matlab R2009b is used as the programming platform. It is indicated by simulation that the computation complexities of SAP and AP-VSM are higher than AP’s, and SAP-LC’s convergence time is the shortest because SAP and AP-VSM adjust the similarity matrix through introducing the concept of pairwise point constraints and manifold space, so extra operation will be added inevitably. Besides, SAP-LC uses the idea of data layering, only processes difficult clustering data on each layer and reduces the computation complexity. Fig.8 Comparison of computation time Advantages and disadvantages of AP clustering algorithm and improved SAP and AP-VSM algorithm are analyzed in the paper. SAP-LC is proposed to improve the accuracy of clustering and reduce the computation complexity. SAP-LC expands the semi-supervised idea, guides clustering through introducing pairwise point constraints and estimates the cluster type by submanifold label mapping. Finally, the accuracy rate and computation time are analyzed theoretically and three evaluation indexes are used to verify the superiorities of SAP-LC in experimental simulation. Next, SAP-LC will be parallelized and combined with the cloud computing platform Hadoop so as to adapt to requirements of big data processing. [1] Demiriz A, Benneit K P, Embrechts M J,etal. Semi-supervised Clustering Using Genetic Algorithm [C]. Proceedings of the Intelligent Engineering Systems through Artificial Neural Networks, New York, 1999: 809-814. [2] Ahmed E B, Nabli A, Gargouri F. A New Semi-supervised Hierarchical Active Clustering Based on Ranking Constraints for Analysts Groupization [J].AppliedIntelligence, 2013, 39(2): 236-250. [3] Yan Y, Chen L H, Tjhi W C. Semi-supervised Fuzzy Co-clustering Algorithm for Document Categorization [J].KnowledgeandInformationSystems, 2013, 34(1): 55-74. [4] Jiao L C, Shang F H, Wang F,etal. Fast Semi-supervised Clustering with Enhanced Spectral Embedding [J].PatternRecognition, 2012, 45(12): 4358-4369. [5] Wang Y Y, Chen S C, Zhou Z H. New Semi-supervised Classification Method Based on Modified Cluster Assumption [J].IEEETransactionsonNeuralNetworksandLearningSystems, 2012, 23(5): 689-702. [6] Gao C F, Wu X J. A New Semi-supervised Clustering Algorithm with Pairwise Constraints by Competitive Agglomeration [J].AppliedSoftComputing, 2011, 11(8): 5281-5291. [7] Bilenko M, Basu S, Mooney R J. Integrating Constraints and Metric Learning in Semi-supervised Clustering [C]. Proceedings of the 21st International Conference on Machine Learning Russ, Banff, 2004: 81-88. [8] Basu S, Bilenko M, Mooney R J. A Probabilistic Framework for Semi-supervised Clustering [C]. Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, 2004: 59-68. [9] Wagstaff K, Cardie C. Clustering with Instance-Level Constraints [C]. Proceedings of the 17th International Conference on Machine Learning, Stanford, 2000: 1103-1110. [10] Yin X S, Hu E L, Chen S C. Discriminative Semi-supervised Clustering Analysis with Pairwise Constraints [J].JournalofSoftware, 2008, 19(11): 2791-2802.(in chinese) [11] Zeng H, Cheung Y M. Semi-supervised Maximum Margin Clustering with Pairwise Constraints [J].IEEETransactionsonKnowledgeandDataEngineering, 2012, 24(5): 926-939. [12] Kamvar S D, Klein D, Manning C D. Spectral learning [C]. Proceedings of the 18th International Conference on Artificial Intelligence, Williamstown, 2003: 561-566. [13] Xu Q J, DesJardins M, Wagstaff K. Constrained Spectral Clustering under a Local Proximity Structure Assumption [C]. Proceedings of the 18th International Florida Artificial Intelligence Research Society Conference, Flairs, 2005: 866-867. [14] Klein D, Kamvar S D, Manning C D. From Instance-Level Constraints to Space-Level Constraints: Making the Most of Prior Knowledge in Data Clustering [C]. Proceedings of the 19th International Conference on Machine Learning, Sydney, 2002: 307-314. [15] Wang L, Bo L F, Jiao L C. Density-Sensitive Semi-supervised Spectral Clustering [J].JournalofSoftware, 2007, 18(10): 2412-2422. (in Chinese) [16] Chandra B, Gupta M. A Novel Approach for Distance-Based Semi-supervised Clustering Using Functional Link Neural Network [J].SoftComputing, 2013, 17(3): 369-379. [17] Schultz M, Joachims T. Learning a Distance Metric from Relative Comparisons [C]. Proceedings of Advances in Neural Information Processing Systems, Cambridge, 2003: 40-47. [18] Lai D T C, Garibaldi J M. A Comparison of Distance-Based Semi-supervised Fuzzy c-Means Clustering Algorithms [C]. Proceedings of 2011 IEEE International Conference on Fuzzy Systems, Taipei, China, 2011: 1580-1586. [19] Tang W, Xiong H, Zhong S,etal. Enhancing Semi-supervised Clustering: a Feature Projection Perspective [C]. Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, 2007: 707-716. [20] Basu S, Banerjee A, Mooney R J. Active Semi-supervision for Pairwise Constrained Clustering [C]. Proceedings of the SIAM International Conference on Data Mining, Cambridge, 2004: 333-344. [21] Yan B, Domeniconi C. An Adaptive Kernel Method for Semi-supervised Clustering [C]. Proceedings of the 17th European Conference on Machine Learning, Berlin, 2006: 18-22. [22] Yeung D Y, Chang H. Extending the Relevant Component Analysis Algorithm for Metric Learning Using Both Positive and Negative Equivalence Constraints [J].PatternRecognition, 2006, 39(5): 1007-1010. [23] Inmar E G, Brendan J F. Semi-supervised Affinity Propagation with Instance Level Constraints [C]. Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, Florida, 2009: 161-168. [24] Xiao Y, Yu J. Semi-supervised Clustering Based on Affinity Propagation Algorithm [J].JournalofSoftware, 2008, 19(11): 2803-2813. (in Chinese) [25] Dong J, Wang S P, Xiong F L. Affinity Propagation Clustering Based on Variable Similarity Measure [J].JournalofElectronics&InformationTechnology, 2010, 32(3): 509-514. (in Chinese) [26] Freund Y, Schapire R E. A Decision-Theoretic Generalization of Online Learning and an Application to Boosting [J].JournalofComputerandSystemSciences, 1997, 55(1): 119-139. [27] Jin R, Kou C H, Liu R J,etal. A Co-optimization Routing Algorithm in Wireless Sensor Network[J].WirelessPersonalCommunications, 2013, 70(2): 1977-1991. Foundation items: the Science and Technology Research Program of Zhejiang Province, China (No. 2011C21036); Projects in Science and Technology of Ningbo Municipal, China (No. 2012B82003); Shanghai Natural Science Foundation, China ( No.10ZR1400100); the National Undergraduate Training Programs for Innovation and Entrepreneurship, China(No.201410876011) TP181 Document code: A 1672-5220(2015)01-0125-07 Received date: 2013- 09- 30 *Correspondence should be addressed to JIN Ran, E-mail: ran.jin@163.com
4 Experiment and Verification










5 Conclusions
 Journal of Donghua University(English Edition)2015年1期
Journal of Donghua University(English Edition)2015年1期
- Journal of Donghua University(English Edition)的其它文章
- Mechanical Property and Crystal Structure of Poly(p-phenylene terephthalamide) (PPTA) Fibers during Heat Treatment under Tension
- Diatomite Precoated Nonwoven Membrane Bioreactor for Domestic Wastewater Reclamation
- Supported Manganese Oxide on Graphite Oxide: Catalytic Oxidation of Nitrogen Oxide in Waste Gas
- Preparation and Properties of Polylactic Acid (PLA)/Nano-SiO2 Composite Master Batch with Good Thermal Properties
- Scheduling Rules Based on Gene Expression Programming for Resource-Constrained Project Scheduling Problem
- Dynamic Analysis of Some Impulsive Fractional-Order Neural Network with Mixed Delay