
深度學習引導的高通量分子篩選用于鍶銫的選擇性配位
2023-11-01 06:58:36張智淵邱雨晴畢可鑫胡孔球戴一陽石偉群
核化學與放射化學 2023年5期
張智淵,董 越,邱雨晴,畢可鑫,胡孔球,戴一陽,周 利,劉 沖,*,吉 旭,石偉群
1.四川大學 化學工程學院,四川 成都 610065;2.中國科學院 高能物理研究所,北京 100049
To meet the carbon neutral agenda globally, development and expansion of nuclear power remains an ideal option to provide electricity for an ever-growing world population while minimizing environmental impacts during operation[1]. State-of-the-art nuclear technologies that hold the promise of a future of clean energy require a closed fuel cycle for safety and sustainability reasons among others, necessitating more research on advanced reprocessing of spent nuclear fuel(SNF). Over the past seven decades, various SNF reprocessing processes have been established to recover critical radionuclides and to reduce radioactive wastes, such as PUREX(plutonium-uranium extraction), UNEX(universal extraction), FPEX(fission product extraction), etc[2]. Among all radionuclides in the high-level liquid waste(HLLW) generated from SNF reprocessing,90Sr and137Cs are major sources for the heat load and radiation[3-5]. Therefore, processes like UNEX were employed to separate90Sr and137Cs simultaneously to lessen the raffinates’ radioactivity, beneficial for downstream operations[3]. Additionally, a further separation between chemically similar90Sr and137Cs could produce valuable materials for radiation therapy, radioisotope thermoelectric generators, industrial gauging devices, etc[3].
In fact, for many SNF reprocessing scenarios, differential coordinative chemical properties of various species are usually the basis to realize successful separation. The same principle is applicable for Sr/Cs separation[6-7], where a large number of coordinating ligands need to be assessed and compared to identify ones with selectivity to achieve preferential coordination(for extraction or crystallization). In our previous work, a machine-learning-guided methodology was developed to rank bridging linkers to form coordination polymers for crystallizing separation of Sr2+over Cs+, in which strengths of coordination bonds were found to be critical in evaluating and comparing different linker molecules’ coordinative affinities and selectivity[8]. Continuing on that, we now propose a more comprehensive study to reliably assess and rank ligands based on their coordinative affinities toward Sr/Cs, using a deep learning(DL) architecture. Specifically, we employ atransformerframework that originated in the field of natural language processing(NLP)[9], specializing in the identification of meaningful segments(e.g., functional groups in molecules) and extraction of contextual information(e.g., structure-property relationships). Moreover, considering the complexities of DL(i.e.,transformer) models and demanding computational burdens thereof, Bayesian optimization(BO) was applied to improve efficiency of the training process[10-11].
An overview of the workflow is shown in Fig.1. The present study started with mining the crystal data of the Cambridge Structural Database(CSD)[12], from which we retrieved information regarding relevant metal-ligand(M-L, M=select 1A/2A metals) pairs and corresponding ligands for subsequent analysis. Next, we trained DL models(i.e.,transformer) using said M-L pairs, which enabled us to systematically evaluate the coordination capabilities of the ligands toward metals of interest. Specifically,to optimize the DL models efficiently, the hyperparameters(HPs) were tuned employing a BO approach. Finally, we ranked the ligands according to their predicted(differential) coordinative affinities for Sr and Cs. We expect that, for a certain ligand, the more different affinities it exhibits toward Cs over Sr(or vice versa), the higher degree of selective coordination is anticipated, hence better separation capability.
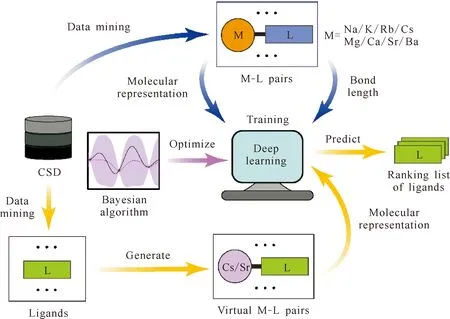
Fig.1 Overview of deep-learning-centered protocol to identify and rank candidate ligands for selective Sr/Cs coordination
1 Methods
1.1 Data mining and molecular representation
Using the CSD Python API[12]provided by the Cambridge Crystallographic Data Centre(CCDC), we were able to extract all M-L pairs and corresponding ligands from crystallographic data that contain 1A(Na, K, Rb, Cs) and 2A(Mg, Ca, Sr, Ba) elements. Then, these data were pre-processed to remove 74 CSD-predefined solvents[13], self-defined free anions/gas molecules[8], and standalone atoms without linkage to ligands. Subsequently, all M-L pairs and ligands were extracted from the pre-processed data. Data pre-processing and extraction of M-L pairs and ligands are illustrated in an example in Fig.2. Next, to be used as input for the DL models, the extracted M-L pairs were linearly represented by the canonical simplified molecular-input line-entry system(canonical SMILES)[14-15]. Along with the molecular structures, structural parameters like bond lengths, bond angles, and coordination numbers could also be extracted from the datasets, among which the coordination bond length was selected as the representative parameter to describe the coordinative affinity or strength of interaction between M and L in a given M-L pair. Additionally, we also extracted 9 169 ligands that would be used for virtual M-L pair generation.
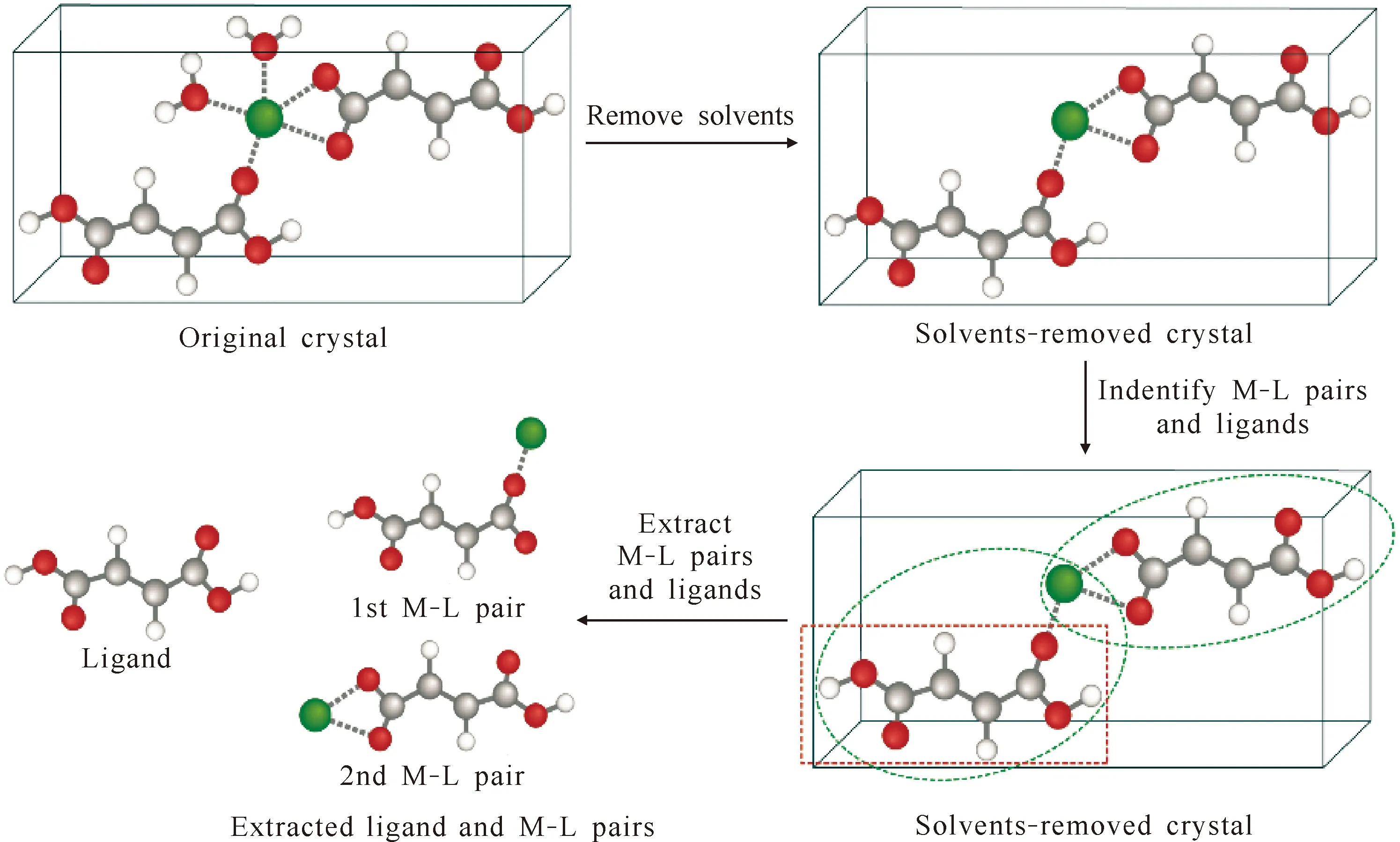
Fig.2 An example of data pre-processing and molecular structure extraction
1.2 Transformer architecture
We usedtransformer[9, 16]as the DL architecture to model the relationship between the molecular structures of M-L pairs and the coordinative affinity(i.e., bond length) of the ligands involved. As shown in Fig.3, thetransformerarchitecture is composed of a word embedding layer, a positional encoding layer, the main body(encoder/decoder) and a multilayer perceptron(MLP) predictor.
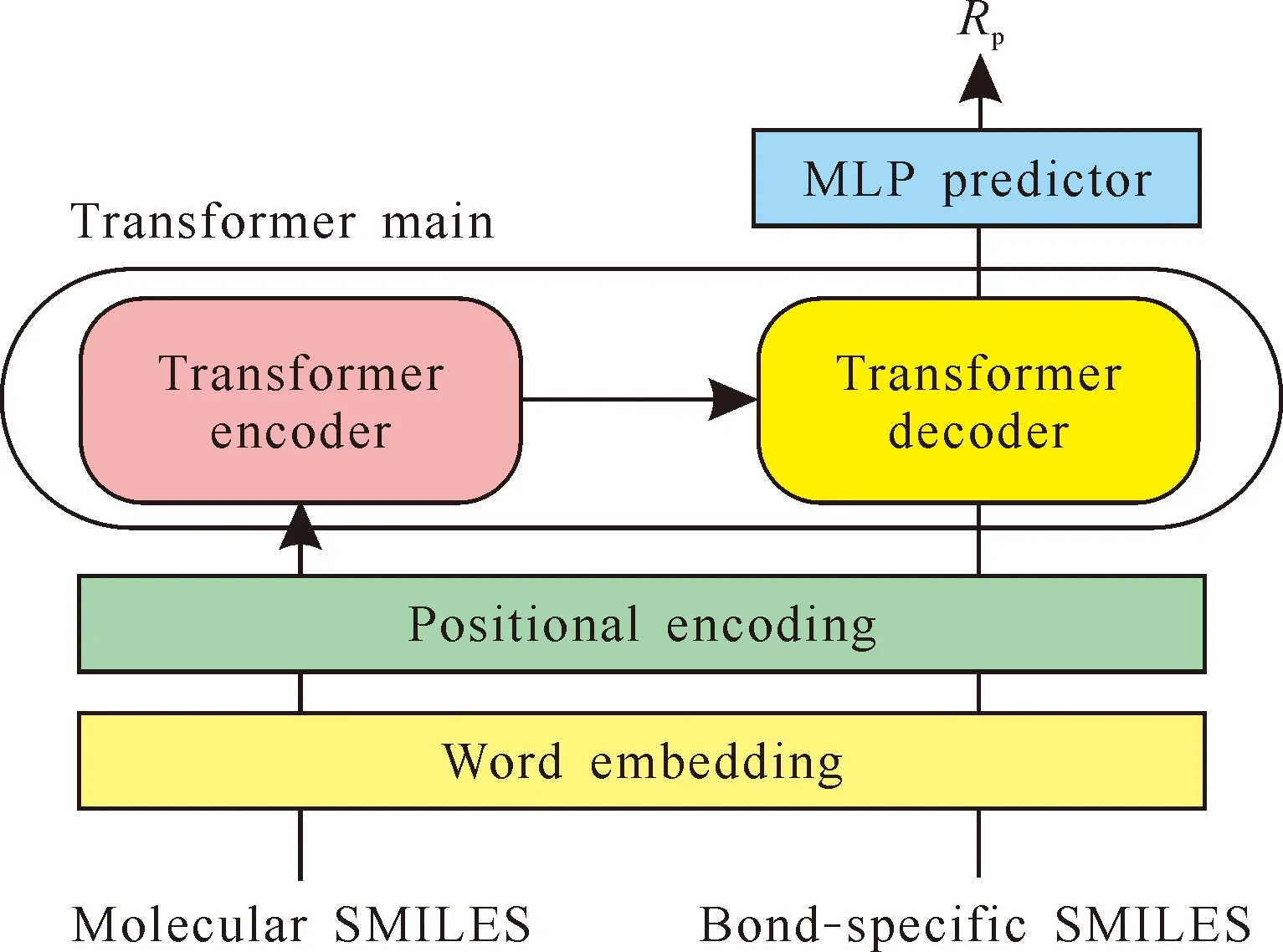
Fig.3 Schematic illustration of transformer architecture
Specifically, the word embedding layer[16]can convert discrete symbolic representation(i.e., the abovementioned SMILES symbols) to continuous vectors, as required by thetransformerarchitecture. The positional encoding layer[17]
compiles the positional information for the sequence of characters in the SMILES, creating another set of vectors to be used as input fortransformermain module. The main oftransformeris composed of encoder and decoder[16]. In short, the encoder can recognize certain combinations of characters in a SMILES sequence, which usually have higher abstract meanings in chemistry than individual characters. Then the decoder would identify which combinations are important for the target(i.e., coordination bond length in our work). Finally, the coordination bond lengths would be predicted by the MLP predictor according to the decoder-proposed important structural combinations.
It should be noted, as illustrated in Fig.3, that two inputs are required for the encoder and decoder oftransformer, respectively. In general, the input for encoder is the complete original SMILES in our dataset. For the decoder, the input should provide information about the specific target of prediction, that is the coordination bond length of a specific bond, considering there are possibly multiple coordination bonds in a given M-L pair.
1.3 Model training and Bayesian optimization
To train thetransformermodels, all M-L pairs were divided into train set, validation set and test set in a ratio of 8∶1∶1. The train set was used to train the models; the validation set was used to validate the performance of trained model and as the “target” for HP optimization; the test set was to test the generalizability of the optimal model. Thetransformermodels were trained by a back-propagation(BP) algorithm[18]and gradient descent to minimize the mean-square-error loss function:
(1)
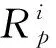
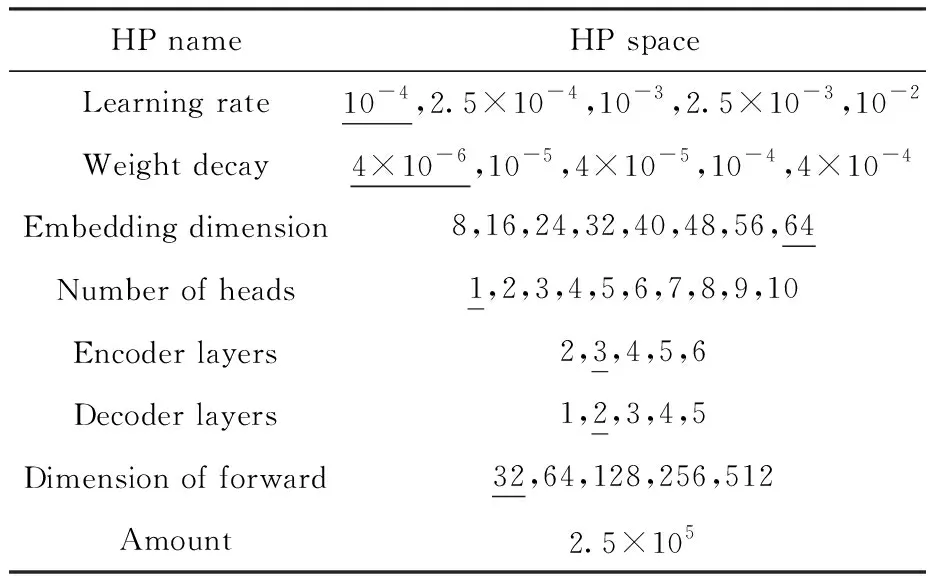
Table 1 HP tuning space
To improve efficiency, we proposed to apply BO algorithm[19-20]to optimize the HPs. As shown in Fig.4(a)(using only a one-dimensional objective function as an example), Gaussian process(GP)[21]and expected improvement(EI)[22]were chosen as the surrogate function and acquisition function, respectively. In our higher-dimensional objective function of HP tuning, GP fits the(unknown) objective function with estimated uncertainties. Consequently, EI proposes the most valuable samples(HPs) to try next. For a given dataset, optimization was performed by applying BO process for 8 batches(4 models per batch). Comparing to manual optimization(Fig.4(b)), the BO approach(Fig.4(c)) was shown to be superior to optimize thetransformermodels, achieving a higherr2(0.927 vs 0.856 for manual) after 8 batches of optimization. As illustrated in Fig.4(d) where the HPs were reduced to a two-dimensional space by t-distributed Stochastic Neighbor Embedding(t-SNE)[23], BO could cover wider parameter space, beneficial for avoiding local optima which constantly challenge manual optimization strategies.
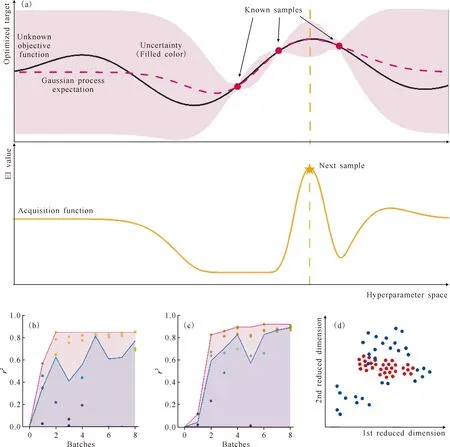
Fig.4 An example of Bayesian optimization on a one-dimensional objective function(top, black curve), using a GP surrogate function(top, magenta curve and pink area) to generate an EI acquisition function(bottom)(a); comparison of manual optimization(b) and Bayesian optimization(c) on coefficients of determination(r2, scattered points) for transformer models, blue line indicates the averaged r2 for models in the current batch, red line indicates the max r2 of trained models so far; distribution of HPs after dimension reduction by t-SNE, where blue and red dots are HPs selected by BO algorithm and manual optimization, respectively(d)
1.4 Ligand assessment
Based on 9 169 ligand molecules extracted from CSD(section 1.1) that contain 12 common coordinating groups(listed in Table 2), Cs-L/Sr-L pairs were generated by virtually bonding the coordinating atoms(e.g., N/O) with Sr/Cs and subsequently represented using SMILES. For the 2×9 169 virtual M-L pairs(i.e., 9 169 Sr-L pairs and 9 169 Cs-L pairs) generated, there is always a Cs-L pair for any Sr-L pair, sharing the identical molecular structure except for the metal, and vice versa, therefore enabling us to predict said L’s different affinity toward Sr/Cs. We grouped each of the 9 169 Sr-L/Cs-L pairs, denoted asGi, wherei=1, 2,…, 9 169.
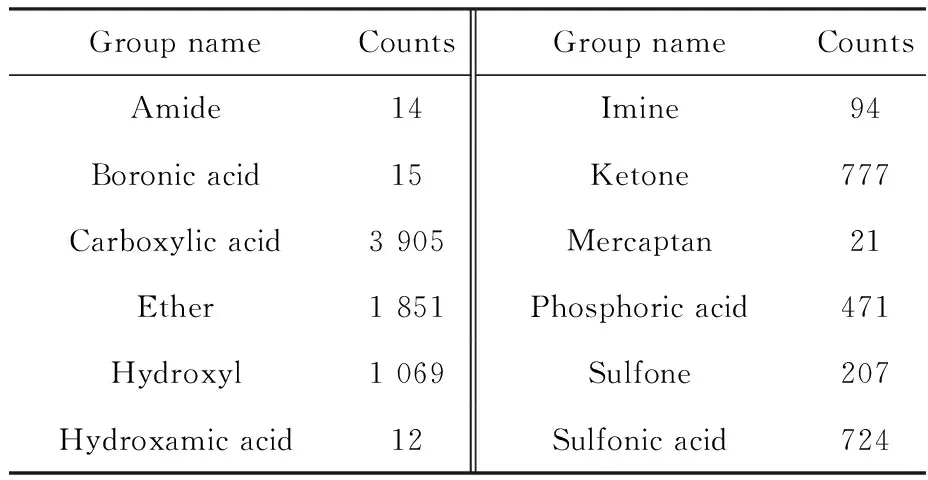
Table 2 Counts of coordinating functional groups for generating virtual (Sr, Cs)-L pairs
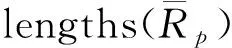
(2)
(3)
2 Results and discussion
2.1 Datasets
After mining of structural data of targeted 1A/2A elements in CSD, we extracted 33 095 M-L pairs, in which 19 467 were mono-coordinated and 13 628 multi-coordinated. A statistical summary is given in Table 3, broken into different elements. In total, these M-L pairs contained 98 411 coordination bonds, i.e., 98 411 samples. It is widely accepted that, for deep learning, to contain as many relevant samples as possible in the training dataset is always beneficial for the model performance[25-27]. Therefore, we argue that all 33 095 M-L pairs(not just ones with Sr/Cs) should be used to train and optimizetransformermodels. Specifically, those M-L pairs containing Na, K, Rb, Mg, Ca and Ba were considered relevant because: 1) they provided information about molecular structures of ligands; and 2) periodicity-dictated elemental similarity in 1A(Na, K, Rb, Cs) and 2A(Mg, Ca, Sr, Ba) groups should lead to similar coordination properties(e.g., coordinating function groups and atoms).
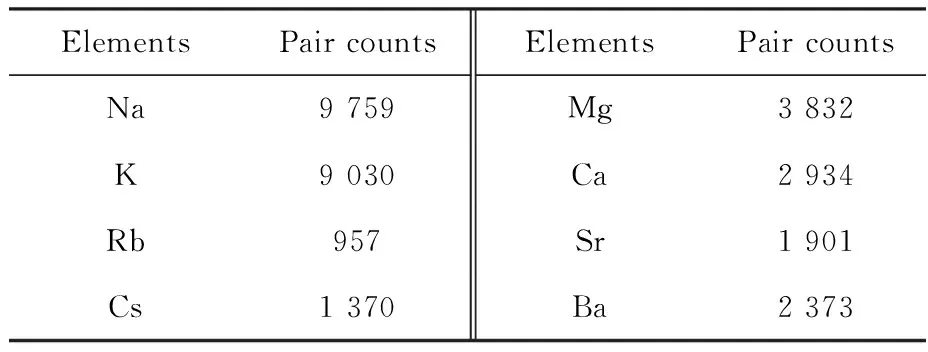
Table 3 Statistics of extracted M-L pairs of specified 1A/2A elements
In order to experimentally confirm this empirical rule and justify our choice of expanded datasets instead of focusing on directly relevant(Sr, Cs)-L samples,transformermodels based on two datasets(i.e., all 33 095 M-L pairs and 4 271(Sr, Cs)-L pairs) were trained and optimized using the same protocol(section 1.3). The mean absolute error(MAE) of the best model based on the dataset of all 33 095 M-L pairs was 0.076 6 ?(1 ?=0.1 nm), 14% less than the best MAE based on 4 271(Sr, Cs)-L pairs, which was 0.088 9 ?.
2.2 Transformer model
As described in section 1.3 and illustrated in Fig.5(a), based on all 33 095 M-L pairs,transformermodel with the highest performance(r2= 0.927 and MAE=0.077 5 ?) on the test dataset was the 21stmodel(its HPs are characterized by the underlined numbers in Table 1) produced by the BO process. The regression diagram and the distribution histogram of absolute error, comparing the model-predicted values against actual coordination bond lengths(i.e., target) for samples in the test dataset, are shown in Fig.5(a) and 5(b), respectively. Overall, thetransformerarchitecture, expanded dataset and BO algorithm have generated a better prediction model comparing to our previous approach[8].
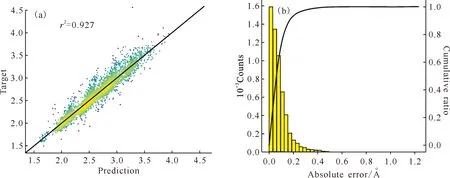
Fig.5 Regression diagram between prediction and target(higher density of scatters is brighter-colored)(a); histogram of absolute error between prediction and target(b)
2.3 Ligand and functional group analysis
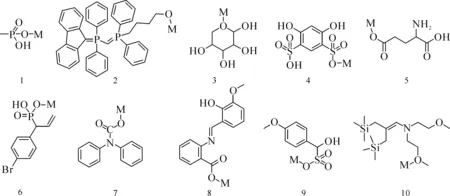
Fig.6 Top 10 identified M-L pairs with the largest
Further, as functional groups usually play critical roles in determining the coordination properties of ligand molecules, the distribution of most frequent 8 coordinating groups(out of 12 that were listed in Table 2) on the ranking list was analyzed. The mean probability density(MPD) of each functional group appearing in the top 1%, 1%-10%, 10%-50% and bottom 50% of the ranking list was calculated by the following:
(4)
WhereNis the total number of virtual M-L pairs(i.e., 9 169),gis the index of functional groups(g=1, 2, …, 8),jis the index of ranking percentages(i.e., 1%, 1%-10%, 10%-50% and bottom 50%, respectively),ngis the amount of functional groupg,pjrepresents the percentage span ofj,cg,jis the count of functional groupgin percentage(range)j. As shown in Fig.7, for any functional groupgin ranking positionj, if MPD(g,j)>1(indicated by the broken line), the occurrence probability(OP) ofginjis greater that the OP ofgin the total list. Therefore, we could conclude that phosphoric acid group, with 3.82 MPD in top 1% and 2.10 MPD in 1%-10%, had the highest probability to be incorporated in a Sr-selective ligand[28-30]. Next in line, hydroxyl, ketone and ether groups showed moderate selectivity toward Sr. Surprisingly, the other common acidic functional groups(i.e., sulfonic acid and carboxylic acid), were not predicted to be coordinatively selective for Sr, which was counterintuitive according to the Hard and Soft Acids and Bases principle as Sr2+is considered a harder Lewis acid than Cs+.
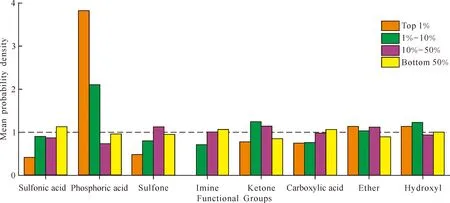
Fig.7 MPD of 8 frequent functional groups in specified ranking percentages
3 Conclusions
In summary, tackling the Sr/Cs separation challenge in SNF reprocessing, we have conducted a deep-learning-guided comprehensive study from the perspective of coordination chemistry. Based on crystal structural data of Sr/Cs and select congeners in respective groups, with the aid of Bayesian optimization, we developedtransformermodels with high performances in predicting coordination bond lengths which were identified as a figure of merit for assessing coordinative affinities. As a proof of concept, we analyzed 9 169 CSD-registered ligands and predicted their differential coordination capabilities toward Sr/Cs, as demonstrated in the top 10 molecular structures and a detailed analysis of functional groups with different potentials for selective coordination toward Sr over Cs. The ranking list of ligands and identification of promising functional groups(e.g., phosphoric acid) would be beneficial for downstream experimental screening and evaluation in separation scenarios.
