
Self-Supervised Entity Alignment Based on Multi-Modal Contrastive Learning
2022-10-29 03:30:08BoLiuRuoyiSongYuejiaXiangJunboDuWeijianRuanandJinhuiHu
Bo Liu, Ruoyi Song, Yuejia Xiang, Junbo Du,Weijian Ruan, and Jinhui Hu
Dear Editor,
This letter proposes an unsupervised entity alignment method, which realizes integration of multiple multi-modal knowledge graphs adaptively.
In recent years, Large-scale multi-modal knowledge graphs(LMKGs), containing text and image, have been widely applied in numerous knowledge-driven topics, such as question answering,entity linking, information extraction, reasoning and recommendation.
Since single-modal information contains unilateral knowledge,which makes LMKGs become more and more important. Considering that we can extract new facts from scratch, it is reasonable and practicable to align existing incomplete knowledge graphs (KGs) to complement each other. Entity alignment (EA) aims at aligning entities having the same real-world identities from different knowledge graphs. Among the studies of EA, there exist two main problems as follows: 1) Most existing EA methods [1], [2] only focus on utilizing textual information, in which the visual modality is yet to be explored for EA. 2) The previous works [1] rely heavily on the supervised signals provided by human labeling, which would cost a lot and may introduce inferior data in constructing LMKGs. As a result, the EA problem remains far from being solved. To demonstrate the benefit from injecting images and help our readers to understand the task of entity alignment, we present an example of“Times” and “泰晤士報” in Fig. 1. Without images, it is possible that “Times” and “clock” will have the similar embeddings. But with image embeddings, it will be more easily to align them.
To solve the above problems, we propose a novel self-supervisedentity alignment method via multi-modal contrastive learning,namely SelfMEA, which embeds text and images [3] in a unified network. The purpose is to increase the accuracy of unsupervised learning and improve the accuracy of automatic entity alignment through contrastive learning and multi-modal method. Concretely, the framework of our method can be divided into two components as shown in Fig. 2, the first is the vectorization and representation of multi-modal knowledge graphs, and the second is the alignment of multi-lingual entities. The former one can be achieved by encoding the embeddings of graph structure, image in knowledge graphs and auxiliary information, and then integrate them to serve as a final embedding.For the latter one, we utilize the corresponding relationship of entities with the same meanings between two graphs through neighborhood component analysis, [4] and iterative learning, so as to realize the multi-language unsupervised entity alignment.

Fig. 1. An example of “Times” and “泰晤士報” of our EA task.
The main contributions of our work are as follows:
1) We propose a novel self-supervised entity alignment method via multi-modal contrastive learning, which is the first work to introduce contrastive learning into multi-modal knowledge for EA and achieve great performance.
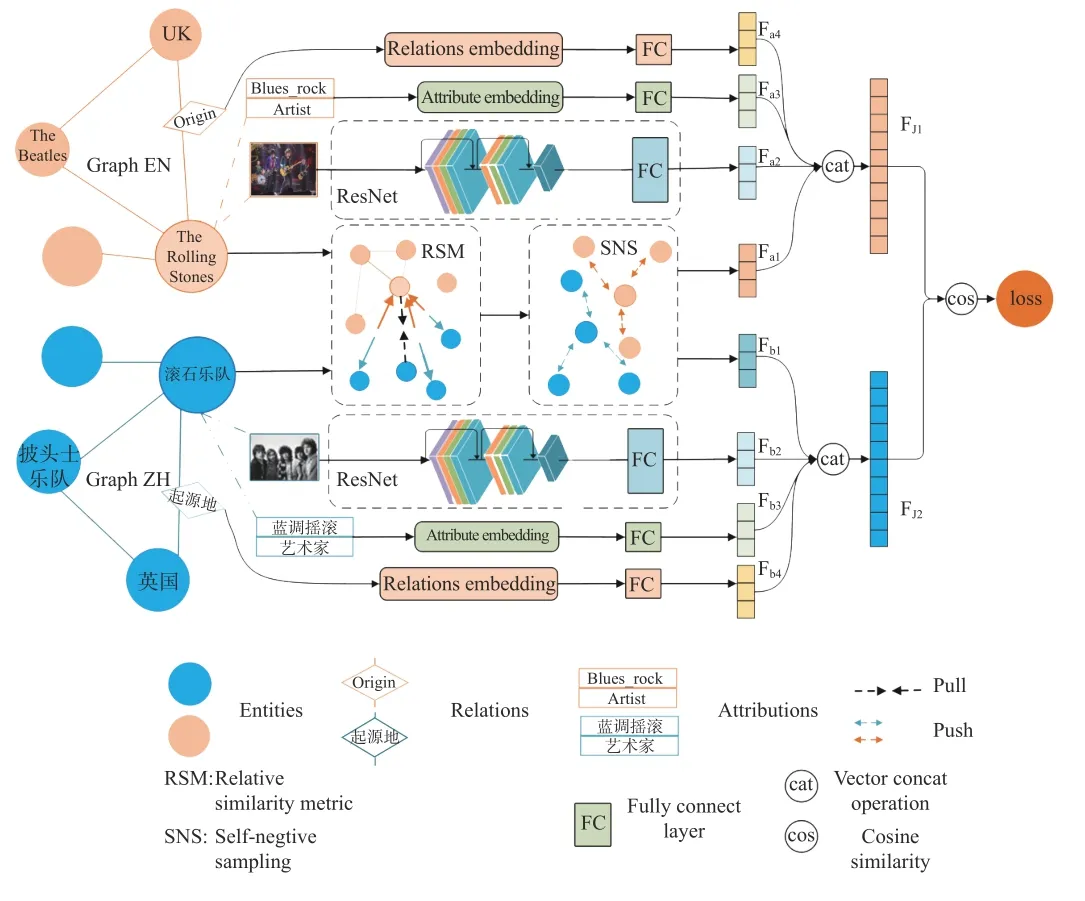
Fig. 2. The flow chart of our SelfMEA.
2) The proposed method provides an effective insight for LMKGs construction, which can avoid expensive labelling cost and break the information unicity of single-modal knowledge graph.
3) Experiments on benchmark data sets DBP15k show that our SelfMEA achieves state-of-the-art performance on multi-modal knowledge graphs entity alignment.

As shown in Fig. 2 we firstly calculate entity embedding, relationship embedding, attribute embedding, and graph structure embedding, and fully connect them as the final embedding. Then we compute the the cosine similarity between the entities from two multilingual knowledge graphs for finding aligned entity. To explain the EA task, we give an example selected from DBP15K(ZH_EN): “The rolling stones” and “滾石樂隊” are entities, which are the entities we need to align. Their relationships, attributes and graph structures are the raw materials used in the model to generate embeddings.
Graph structure embedding: Entity expressions of different knowledge graphs are distributed in different vector spaces. In this work, we use LaBSE, another most advanced multilingual pretrained language model to map entity expressions to the same space.In the alignment task, [2] demonstrates that it is more effective to stay away from negative samples than to draw close to positive samples So, according to this discovery, we use contrastive learning in constructing graph structure embedding. When constructing this part,we use the absolute similarity metric (ASM) theorem [2]. Based on ASM, the relative similarity metric (RSM) is proposed. For fixed τ >0 and encoderfqualifications ‖f(·)‖=1, we have

Attribute and relation embedding: Entity attributes and relationship also contain abundant information. Reference [6] found that spatially adjacent entities may interfere with each other, thus polluting entity representations in the GCN modeling process, which we don't want to see. Therefore, SelfMEA adopts a simple full connection layer to map relationship and attribute features to low-dimensional space, thus reducing the dimensions of entity attributes and relationship.

Iterative learning: Iterative learning control has been an active research area for more than a decade. Since SelfMEA is an unsupervised learning model, in order to improve the effect of the model without labels, we refer to [3] and adopt iterative learning strategy to propose more seeds from unaligned entities. Once epoch loops to a specific node, we will put forward a new round of suggestions and add each pair of intersection graph entities in the nearest neighbor to the candidate list. Therefore, the list of candidates will be updated in certain epochs, which yields a stable iteration greatly by enlarging seeds pool. The algorithm of obtaining the candidate list is described in Algorithm 1.
Experimental results: We conduct extensive experiments on DBP15k [7] dataset, as well as images obtained from Wikipedia, to evaluate the proposed SelfMEA. The DBP15k dataset contains three pairs of graph correspondences in different languages, namely, Chinese and English (zh_en), French and English (fr_en), and Japaneseand English (ja_en). Each pair has 15K pairs of aligned entities, of which 60% are selected as the test set and the rest as the verification set. There are about 165k-222k relationships in each subdataset, and the three relational datasets have 2k-3k classes. The proportion of images in each data set is about 66%-78%. We conduct comparisons with 8 state-of-the-art methods on DBP15k dataset, as shown in Table 1. The evaluation results indicate that the proposed SelfMEA outperforms the other unsupervised classical alignment models,Specifically, our SelfMEA model leads to 4-5% absolute improvement in H@1 over the best baseline. This shows that the multi-modal method with contrastive learning can effectively improve the representation of cross language entities and infer their correspondence without additional supervision tags. There are obvious gaps between different subdatasets. For example, in ZH_EN, all the methods achieve the smallest Hit@1, Hit@10, and mean reciprocal rank(MRR), while achieve the middle in JA_EN, and the best in FR_EN.This phenomenon can be attributed to that there are more relationships between entities in the FR_EN dataset, and fewer types of relationships, thus the graph structure embeddings can better capture the information in FR_EN than ZH_EN and JA_EN. In addition, when obtaining graph structure embedding, we also tried to add pictures to the comparative learning model. As a result, the subtask was slightly improved, but the application was not improved on SelfMEA.
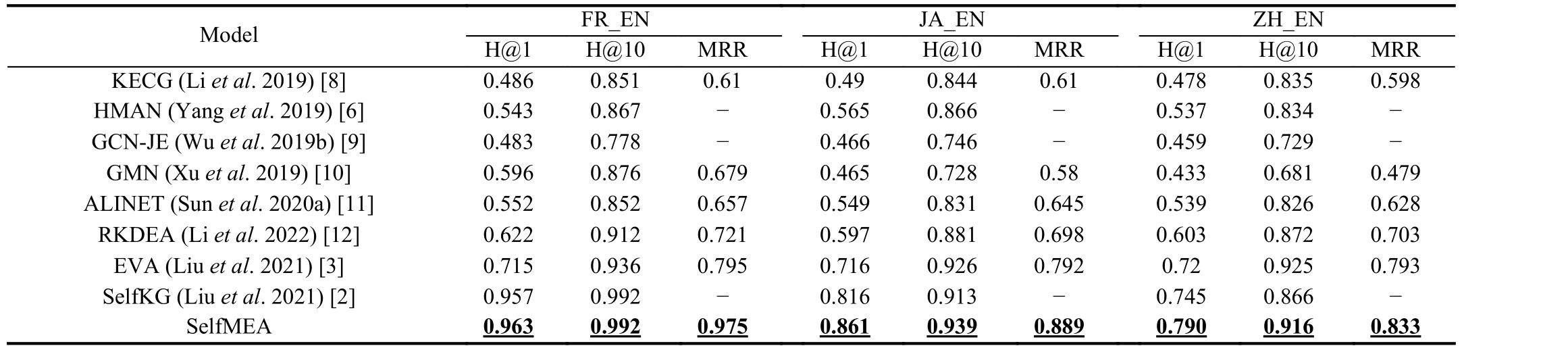
Table 1.Comparison With the State-of-the-Art Methods and SelfMEA Results on DBP15k. “-” Means not Reported by the Original Paper. Underlined Bold Numbers are the Best Models

Algorithm 1 Iterative Learning Input: Image embeddings of entities from two graphs , ; new size n Output: The new candidate list S M=<F1,F2 >F1 F2 1: Similarity matrix ;2: Sort elements of M;S!=n 3: While do m.ri ?Ru&m.ci ?Cu 4 if then S ←S ∪(m.ri,m.ci)5 ;Ru ←Ru ∪m.ci 6 ;Cu ←Cu ∪m.ri 7 ;8 return new train list 9 end 10 end
Conclusion: We propose a multi-model self-supervised method with contrastive learning for entity alignment in this letter, which can break the information unicity of single-modal knowledge graph and avoid expensive labelling cost. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods. In the future, we plan to supplement the image dataset of DBP15K, and further improve the model accuracy through enhancing the interaction between information in different modality.
Acknowledgments: This work was supported by the National Key Research and Development Project (2019YFB2102500) and the National Nature Science Foundations of China (U20B2052).
 IEEE/CAA Journal of Automatica Sinica2022年11期
IEEE/CAA Journal of Automatica Sinica2022年11期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Collective Entity Alignment for Knowledge Fusion of Power Grid Dispatching Knowledge Graphs
- Frequency Regulation of Power Systems With a Wind Farm by Sliding-Mode-Based Design
- Adaptive Generalized Eigenvector Estimating Algorithm for Hermitian Matrix Pencil
- A Bi-population Cooperative Optimization Algorithm Assisted by an Autoencoder for Medium-scale Expensive Problems
- A Zonotopic-Based Watermarking Design to Detect Replay Attacks
- Receding-Horizon Trajectory Planning for Under-Actuated Autonomous Vehicles Based on Collaborative Neurodynamic Optimization