
Screening dementia and predicting high dementia risk groups using machine learning
2022-04-01 07:15:30HaewonByeon
World Journal of Psychiatry 2022年2期
Haewon Byeon
Haewon Byeon,Department of Medical Big Data,Inje University,Gimhae 50834,South Korea
Abstract New technologies such as artificial intelligence,the internet of things,big data,and cloud computing have changed the overall society and economy,and the medical field particularly has tried to combine traditional examination methods and new technologies.The most remarkable field in medical research is the technology of predicting high dementia risk group using big data and artificial intelligence.This review introduces:(1) the definition,main concepts,and classification of machine learning and overall distinction of it from traditional statistical analysis models;and (2) the latest studies in mental science to detect dementia and predict high-risk groups in order to help competent researchers who are challenging medical artificial intelligence in the field of psychiatry.As a result of reviewing 4 studies that used machine learning to discriminate high-risk groups of dementia,various machine learning algorithms such as boosting model,artificial neural network,and random forest were used for predicting dementia.The development of machine learning algorithms will change primary care by applying advanced machine learning algorithms to detect high dementia risk groups in the future.
Key Words:Dementia;Artificial intelligence;Clinical decision support system;Machine learning;Mild cognitive impairment
lNTRODUCTlON
New technologies such as artificial intelligence,the internet of things,big data,and cloud computing have appeared with the advent of the Fourth Industrial Revolution.These new technologies have changed the overall society and economy,and the medical field particularly has tried to combine traditional examination methods and new technologies.The most remarkable field in medical research is the technology of predicting high-risk groups using big data and artificial intelligence.The picture archiving and communication system and electrical medical records have been implemented in hospitals over the past 20 years,and it has accumulated an enormous amount of medical data.However,there is a limit to analyzing patterns or characteristics of the data using only traditional statistical methods due to the size (volume) and complexity of such medical big data.
However,studies have persistently predicted dementia based on machine learning[1-5] over the past 10 years by using cognitive abilities such as neuropsychological tests,in addition to brain imaging and image analysis,which has shown new possibilities for screening dementia and predicting groups with high dementia risk based on medical artificial intelligence.It is expected that the clinical decision support system (CDSS) using artificial intelligence including machine learning will be widely introduced in medical research and it will affect disease prediction and early detection.It is critical to collect high-quality data and analyze the data with an appropriate machine learning technique suitable for the properties of the data to create safe and meaningful medical artificial intelligence.It is necessary to understand the characteristics of machine learning algorithms,different from traditional statistical methods,in order to develop a CDSS that is scientifically meaningful and shows good performance with the participation of medical experts in this process.
Machine learning has been widely used over the past 20 years mainly because of the emergence of big data[6].It is because the performance of machine learning mostly depends on the quantity and quality of data,and the required level of data has become available only recently.The amount of digital data produced worldwide has been skyrocketing,and it is forecasted that it will be 163 zettabytes per year in 2025[7].Big data that can be used for medical research include electronic medical record and picture archiving and communication system data individually constructed by a medical institution,insurance claim data of the Health Insurance Corporation,and epidemiological data such as the National Health and Nutrition Examination Survey data.More mental science studies[8,9] have tried to identify risk factors for mental disorders such as depression and cognitive disorders such as dementia using these epidemiological data.
Machine learning algorithms have been successfully applied in medical image processing fields such as neurology and neurosurgery.However,mental science,which mainly deals with clinical data(structured data) such as cognition and emotion,has relatively fewer studies on disease prediction using machine learning.Furthermore,researchers in mental science do not have a deep understanding on machine learning,either.This review introduces:(1) The definition,main concepts,and classification of machine learning and overall distinction of it from traditional statistical analysis models;and (2) The latest studies in mental science to detect dementia and predict high-risk groups in order to help competent researchers who are challenging medical artificial intelligence in the field of psychiatry.
DEFlNlTlON OF MACHlNE LEARNlNG
The machine learning technique is a representative method for exploring the risk factors or high-risk groups of a disease by analyzing medical big data (Figure 1).Many studies mix the concepts of artificial intelligence,machine learning,and deep learning.Machine learning means the algorithm for data classification and prediction,while deep learning is the algorithm that is composed of an input layer,multiple hidden layers,and an output layer,imitating human neurons,among many machine learning algorithms.Moreover,artificial intelligence can be defined as the highest concept encompassing both deep learning and machine learning.Traditional statistical techniques such as analysis of variance and regression analysis can also be used for analyzing big data.However,traditional statistical techniques cannot identify the complex linear relationships among variables well because big data contain multiple independent variables,and they are limited in analyzing data with many missing values.
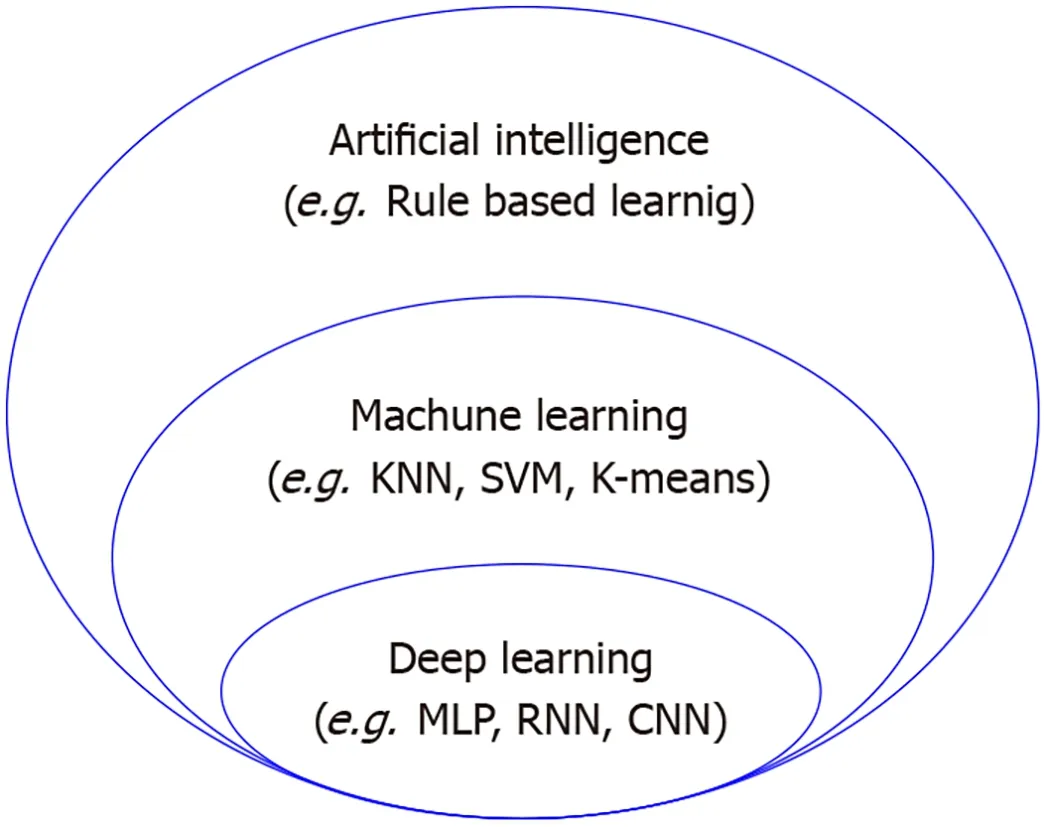
Figure 1 Diagram for concepts of artificial intelligence,deep learning and machine learning.
Machine learning refers to a method of improving the performance of an algorithm by itself through learning from data.Mitchell[10],a world-renowned machine learning scientist,defined machine learning using task,experience,and performance measure.If there is a computer program,which gradually performs a task better as it accumulates experience through performance measures,it is considered that learning has been accomplished in that computer program.In other words,machine learning is a method that allows a computer to learn using data and finds an optimal solution as a result of it.
In general,machine learning algorithms develop various machine learning models to predict disease risk factors and select the model showing the best performance as the final model.While traditional statistical techniques such as regression analysis use the significance probability to evaluate the predictive performance of models,machine learning algorithms use a loss function.Mean squared errors and mean absolute errors are used as loss functions to evaluate the performance of machine learning for continuous variables,while cross entropy is used for categorical variables[11].If there are many model parameters or there is a possibility to misrepresent the result due to biased parameters,regularization,a method of adding a penalty to a loss function,is used.L1 (lasso) regularization and L2(ridge) regularization are representative regularizations used in machine learning,and the Akaike information criterion and Bayesian information criterion are also used[12].
EVALUATlNG THE PREDlCTlVE PERFORMANCE OF MACHlNE LEARNlNG MODELS
Generally,hold-out validation and k-fold validation are mainly used to evaluate the predictive performance of machine learning models.Hold-out validation validates the accuracy by separating the dataset into a training dataset and a test dataset (Figure 2A).For example,80% of the dataset is used as a training dataset to train a learning model,and the remaining 20% is used as a test dataset to evaluate predictive performance (accuracy).However,if the size of data is not large enough,the hold-out validation may suffer from overfitting.The k-fold validation can be used as an alternative to overcoming the limitation of the hold-out validation.The k-fold validation divides the data into k groups,uses each group as a verification group,and selects the model with the smallest mean error(Figure 2B).

Figure 2 The concept of two validations.
THE STRENGTH OF MACHlNE LEARNlNG lN PREDlCTlNG HlGH DEMENTlA RlSK GROUPS
Many previous studies[4,5] did not define the high dementia risk group as a dementia group because although their memory or cognitive functions were lower than the group with the same age and education level in a standardized cognitive test,the ability to perform daily life (e.g.activities of daily living) was preserved.In other words,since it is the preclinical stage of dementia,it has been receiving attention in terms of early detection and prevention of dementia.
In general,the main goals of data analysis for predicting high dementia risk groups are inference and prediction.The inference is based on theories and previous studies,and it assumes that data is generated by a specific statistical-based model and tests hypotheses established by the researcher.Even though traditional statistical analyses emphasize inference,prediction using machine learning,unlike inference,often does not establish hypotheses or does not conduct hypothesis testing.Therefore,statistical learning can be considered more advantageous than machine learning in analyzing social science data (or mental science data) emphasizing the relationship between variables.However,as convergence studies on disease prediction have been active recently,this comparison is gradually becoming meaningless.In other words,it has become more common not to strictly distinguish terminologies such as machine learning,statistical analysis,and predictive analysis.Nevertheless,the followings are the strengths of machine learning over traditional statistical analyses.First,it is important to build a predictive model and identify the relationship between key variables associated with the issue in traditional statistical analyses.On the other hand,machine learning focuses on identifying patterns and exploring predictive factors of dementia rather than testing a specific hypothesis.Therefore,machine learning techniques can be applied more flexibly to more diverse data than traditional statistical analysis techniques.
Second,while traditional statistical analysis techniques focus on linear models,machine learning has the advantage of handling nonlinear models and complex interactions between variables[13].
Third,machine learning can analyze a large amount of data that are difficult to handle with traditional statistical methods.Data generally used in statistics are called “l(fā)ong data” and they refer to data in which the number of cases exceeds the number of variables,while “wide data” indicate data in which the number of variables is larger than the number of cases[14].Even though it is hard to analyze wide data with traditional statistical techniques,machine learning has the advantage that it can analyze long data as well as wide data easily.In other words,while traditional statistical techniques are optimized to analyze data collected through researchers' research design,machine learning can analyze large volumes of data collected without a specific intention.
LlMlTATlONS OF MACHlNE LEARNlNG lN PREDlCTlNG HlGH DEMENTlA RlSK GROUP
The limitations of machine learning in detecting dementia or predicting high dementia risk groups are as follows.First,it is difficult to interpret the relationship between explanatory variables and response variables with black-box techniques (e.g.,boosting models,artificial neural networks,and random forests) among machine learning techniques.While traditional statistical analysis techniques aim to explain (interpret) the relationship between independent and dependent variables,the goal of machine learning techniques is to predict.For example,studies that aim to infer high dementia risk groups develop a study model based on theories and previous studies and test hypotheses.It is possible to explain the characteristics of these high dementia risk groups through the model.On the other hand,studies that aim to predict usually don’t have a clear study model and often don’t test a hypothesis.However,it is possible to confirm which variables are critical to predicting dementia.In particular,when there are new learning data,even if dementia does not develop,it has the advantage of providing the necessary help to the high dementia risk group by categorizing the elderly in the community into a high-risk group and a low-risk group.In summary,traditional statistical analyses emphasize inference,and machine learning focuses on prediction.Machine learning models such as random forests and neural networks partially overcome the issues of the black box by visually presenting the relative importance of variables using “variable importance” and “partial dependence plot”.However,it still has limitations in interpreting the relationship or causality between variables.
Second,it may be difficult for mental science researchers to understand machine learning techniques that emphasize the accuracy of prediction rather than explaining the relationship between variables and do not focus on inference of hypotheses.Among the machine learning techniques,the penalized regression model,which is relatively close to the traditional statistical model,presents which explanatory variable is related to the response variable in which direction and how much,but it generally does not show the statistical significance of the explanatory variable like the linear regression model.
Third,unlike the traditional statistical model that models a small number of variables for a theoretical test,the machine learning technique is data-driven.Therefore,unless the data are unbiased good quality data,it is highly likely that biased results will be derived.
TYPES OF MACHlNE LEARNlNG
Regression algorithm
Regression models based on stepwise selection have very poor performance in high-dimensional models.Therefore,it is compensated by using the regulation method,which gives a penalty every time the number of variables is increased.Lasso regression is a representative method[15].In order to reduce the effect of outliers or singularity in the data,a robust regression technique that selects and trains a part of the data and reiterates this process can also be used[16].
Clustering algorithms
The clustering algorithm classifies data into a specified number of clusters according to the similarity of the attributes.Since the data have only attribute values and labels do not exist,it is called unsupervised learning.The k-means algorithm is a representative clustering algorithm.
Classification algorithms
Classification algorithms include decision tree (DT),support vector machine (SVM),k-nearest neighbor,and multilayer perceptron (MLP) ensemble learning.It is important to treat the imbalance of y-class when applying the classification algorithm.If there is an imbalance of classes,the group with a larger number of data is treated as more important,and the predictive performance decreases.Undersampling,oversampling,and synthetic minority over-sampling technique (SMOTE) methods are mainly used to deal with data imbalance[17],and it has been reported that the performance of SMOTE is generally better than that of undersampling and oversampling[18].
DT
DT is a classifier that repeats binary classification based on the threshold value of a specific variable to the desired depth.Classification criteria variables and values are automatically learned from the data.The classification and regression tree algorithm is used for the learning of DT,instead of gradient descent.This method adds nodes step by step to minimize Shannon entropy or Gini index.The advantage of DT is that the learned classification results can be easily understood by people.
SVM
SVM is a machine learning algorithm that finds the optimal decision boundary through linear separation that separates the hyperplane optimally.If data have a non-linear relationship,the same method is applied after transforming the input variable using a kernel function.SVM solves nonlinear problems related to input space (e.g.,two-dimension) by transforming it into a high-dimensional feature space.For example,when A=(a,d) and B=(b,c) are non-linearly separable in 2D,it has linearly separable characteristics if they are mapped in 3D.Thus,when adequate nonlinear mapping is used in a sufficiently large dimension,data with two classes can always be separated in the maximum-margin hyperplane.The advantage of SVM is that it can model complex nonlinear decision-making domains.
MLP
Until the late 20thcentury,studies using artificial neural networks used shallow networks with two or less hidden layers[19].However,as the effectiveness of deep neural networks was confirmed in the 21stcentury[19],the dropout technique and a rectified linear unit function were developed after 2010[20].Through them,the era of deep learning has begun.The advantage of MLP is its excellent accuracy.Since the accuracy of deep neural networks is generally higher than that of shallow networks[21],it is recommended to apply deep neural networks to obtain more accurate classification or prediction in disease data.Although deep neural networks generally have slightly higher accuracy than other machine learning models,the learning time of it is longer[22].Therefore,researchers need to select an algorithm suitable for the purpose when developing a machine learning model.
Ensemble learning methods
Ensemble learning refers to a method to learn many models using only some samples or some variables of the data and use these models at the same time,which usually provides better predictive performance than when using a single model.Bootstrap aggregating (bagging) and boosting are representative ensemble learning techniques.Bagging is a method of determining the final output by fitting the result variables several times using some samples or only some variables of the training dataset[23].Bagging shows good performance because as the number of classifiers increases,the variance of the prediction means of the classifiers decreases.Boosting refers to a method of sequentially generating multiple classifiers.The bagging of DT and random forest are typical examples of the ensemble learning technique.Fernandez-Delgadoet al[24] compared the performance of classifiers for 121 datasets and reported that random forest impressively outperformed the rest 179 classifiers.
STUDlES OF PREDlCTlNG DEMENTlA BASED ON MACHlNE LEARNlNG
Most of the previous studies[25,26] on the detection of dementia and the prediction of high-risk groups used traditional statistical methods such as regression analysis or structural equation models,but some studies[2-5] applied machine learning (Table 1).Previous studies using machine learning techniques for the elderly with dementia predicted dementia,mild cognitive impairment,and very mild dementia using various features including demographic information[2],medical records[2-5],dementia test scores[3,4],and normalized whole-brain volume[2].Previous studies have shown that machine learning models had different predictive performance.Bansalet al[2] reported that the accuracy (99.52) of the DT model (J48) had the highest accuracy compared to other machine learning models (e.g.,na?ve Bayes,random forest,and MLP).On the other hand,Zhuet al[4] revealed that the accuracy (predictive performance) of MLP (87%),naive Bayes (87%),and SVM (87%) was excellent.Jammehet al[5]confirmed that the area under the curve (AUC) (predictive performance) of naive Bayes (AUC=0.869)was the best compared to other machine learning models.The predictive performance of machine learning techniques varies among studies because of the difference in machine data (especially,Y variables) imbalance,characteristics of features included in the model,and measurement methods of outcome variables.Therefore,further studies are continuously needed to check the predictive performance of each algorithm because,although some studies have proven that the performance of a specific machine learning algorithm is excellent,the results cannot be generalized for all types of data.
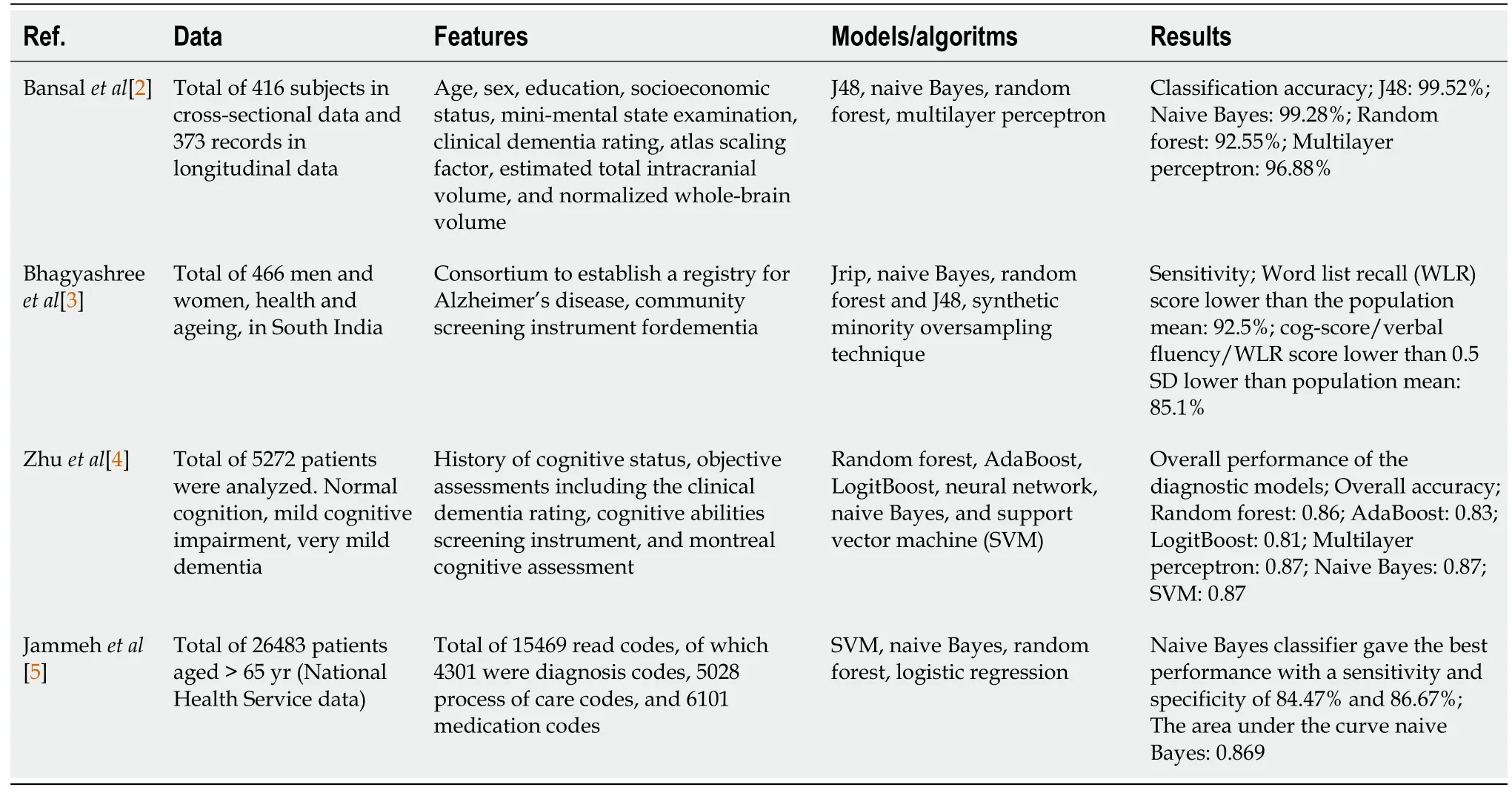
Table 1 Summary of studies
CONCLUSlON
This study introduced the definition and classification of machine learning techniques and case studies of predicting dementia based on machine learning.Various machine learning algorithms such as boosting model,artificial neural network,and random forest were used for predicting dementia.After the concept of deep learning was introduced,multilayer perceptron has been mainly used for recognizing the patterns of diseases.The development of machine learning algorithms will change primary care by applying advanced machine learning algorithms to detect high dementia risk groups in the future.If researchers pay attention to machine learning and make an effort to learn it while coping with these changes,artificial intelligence technology can be used as a powerful tool (method) for conducting mental science studies.
FOOTNOTES
Author contributions:Byeon H designed the study,involved in data interpretation,preformed the statistical analysis,and assisted with writing the article.
Supported bythe Basic Science Research Program through the National Research Foundation of Korea funded by the Ministry of Education,No.2018R1D1A1B07041091 and 2021S1A5A8062526.
Conflict-of-interest statement:No benefits in any form have been received or will be received from a commercial party related directly or indirectly to the subject of this article.
Open-Access:This article is an open-access article that was selected by an in-house editor and fully peer-reviewed by external reviewers.It is distributed in accordance with the Creative Commons Attribution NonCommercial (CC BYNC 4.0) license,which permits others to distribute,remix,adapt,build upon this work non-commercially,and license their derivative works on different terms,provided the original work is properly cited and the use is noncommercial.See:http://creativecommons.org/Licenses/by-nc/4.0/
Country/Territory of origin:South Korea
ORClD number:Haewon Byeon 0000-0002-3363-390X.
S-Editor:Zhang H
L-Editor:A
P-Editor:Zhang H
 World Journal of Psychiatry2022年2期
World Journal of Psychiatry2022年2期
- World Journal of Psychiatry的其它文章
- Burnout amongst radiologists:A bibliometric study from 1993 to 2020
- Catatonia in older adults:A systematic review
- Cross-sectional study of traumatic stress disorder in frontline nurses 6 mo after the outbreak of the COVlD-19 in Wuhan
- lmportance of communication in medical practice and medical education:An emphasis on empathy and attitudes and their possible influences
- Reduced paraoxonase 1 activities may explain the comorbidities between temporal lobe epilepsy and depression,anxiety and psychosis
- Associated mortality risk of atypical antipsychotic medication in individuals with dementia